Overview
Features for parsing, processing and formatting of XML documents in SuperCollider are provided by the classes DOMDocument, DOMNode and related DOM-classes. The Document Object Model (DOM) is a standardized set of interfaces for representing XML documents in an object-oriented structure, making them handable for processing with an object-oriented programming language. Here is an implementation of the DOM concepts for SuperCollider.
Areas of application
The DOM implementation allows 4 basic kinds of operations:
- parse XML documents from a file or string
- process the data once it has been parsed, i.e. retrieve data from the object-structure and optioanlly change it
- create XML documents and content-nodes as object-instances in memory
- output formatted XML documents to a file or as string
Download
XML parsing and formatting - Download
Class DOMDocument
The central class for handling XML documents is DOMDocument. From the source-code:
// DOMDocument is the main class for acessing XML documents.
// This class and all related DOMXxx-classes implement a subset of the DOM-Level-1
// specification for XML parsers, adopted to the the SuperCollider language. See
// http://www.w3.org/TR/REC-DOM-Level-1/level-one-core.html for the full level 1
// specification of the Document Object Model (DOM).
// -
// All interfaces specified by the DOM, if used at all in this implementation, are
// directly mapped to SuperCollider classes. The original interface inheritance
// hierarchy is thus preserved in the class hierarchy (which is not necessarily
// required for the implementation of interfaces, see DOM-Level-1, 1.1.2).
// -
// Classes implementing the DOM interfaces are:
// DOMDocument -
// The central class for accessing XML documents. This is the only
// class whose instances get created using 'DOMDocument.new', instances of any
// other class are either created internally during parsing of an XML-string,
// or programmatically through calls on 'DOMDocument.createElement(..)',
// 'DOMDocument.createText(..)', etc.
// DOMElement -
// Represents an XML-tag.
// DOMAttr -
// Represents an attribute of an XML-tag. The implementation considers this class as
// a helper class and only partially implements the DOM specification of DOMAttr.
// Attribute values should only be accessed via the corresponding
// getAttribute, setAttribute methods of DOMElement.
// DOMCharacterData -
// Abstract class. This is the common superclass of all nodes in the document which
// carry free-form string content.
// DOMText -
// Text in the document.
// DOMComment -
// Comment in the document (ignored by default during parsing, set DOMDocument.parseComments=true to
// get access to comment nodes).
// DOMCDATASection -
// Raw text section.
// DOMProcessingInstruction -
// Processing instruction nodes.
// DOMNode -
// The common superclass of all nodes. Each node can also be accessed via the
// methods of this class only, which the DOM calls a 'flat'-access to the document
// nodes (flat in terms of meta-model classes, the document-structure of course
// is always composed of nodes in a tree structure described by the parent-children
// relationship, see DOM-Level-1, 1.1.4).
// -
// Some interfaces specified in the DOM-Level-1 are not implemented by this
// adoption:
// DOMString -
// Not implemented, SuperCollider's own String class is used for best integration
// into SuperCollider.
// NodeList, NamedNodeMap -
// Not implemented, SuperCollider's own collection classes are used for best integration
// into SuperCollider.
// DOMException -
// Not implemented, in most cases errors will result from SuperCollider's own
// exception handling, especially in cases of errors resulting from collection classes.
// Parse errors are handled by method DOMDocument.parseError which by default
// will simply output a text message and exit the program. This might be
// overwritten for a more subtle handling of parse errors.
// DOMDocumentType, DOMNotation -
// Not implemented. DTDs are no longer up-to-date technology anyway (use XML-Schema
// instead), and in most cases it will not be necessary to validate an XML document
// from within SuperCollider. External tools could easily be used in cases where
// DTD-based validation is required.
// Calling DOMDocument.getDoctype will always return nil (as allowed by the
// specification, see DOM-Level-1, 1.3). During parsing, doctype declarations will be
// treated like comments.
// DOMEntity, DOMEntityReference -
// Not implemented, only a fixed set of simple character-entities in Text-nodes
// is supported.
// -
// As a notation convention, all methods marked as 'public' ('+') in the UML class diagram
// belong to the implementations of DOM interfaces.
// In contrast to that, all methods marked as 'friendly' ('~') are additions specific to this
// SuperCollider-implementations. The code generated from the class diagram does,
// however, not distinguish between different levels of visibility, so the 'friendly' methods
// are still publicly accessibly from any other SuperCollider class.
// (There are also methods marked as 'protected' ('#'), these are intended to be internal
// methods of the implementation. They should not be called from outside code.)
// -
// Note: The DOM-Level-1 specification covers version 1.0 of the XML standard only.
// Newer versions of the DOM also include features like XML namespaces, which are
// explicitly not supported by this adoption, but might not be required for most
// applications within SuperCollider anyway.
See also the Document Object Model (DOM) and the DOM-Level-1 specification for a documentation of the semantics of the DOMXxx-classes at http://www.w3.org/TR/REC-DOM-Level-1/.
Examples
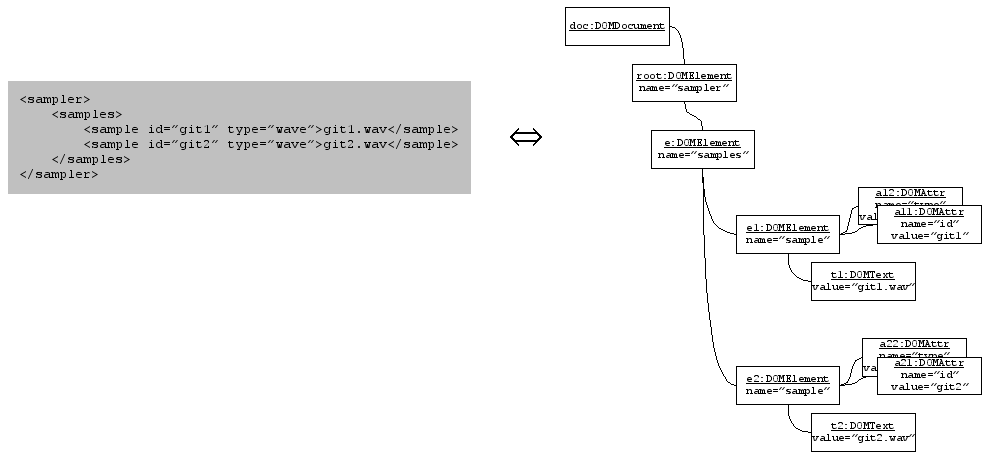
The following XML file 'sampler.xml' is used here as an example:
<!-- This is a dummy XML-file for testing SuperCollider's DOM-implementation. -->
<sampler>
<!-- This section contains sample-references. -->
<samples>
<sample id="git1" type="wavefile">/data/samples/git1.wav</sample>
<sample id="git2" type="wavefile">/data/samples/gits.wav</sample>
</samples>
<!--
This section contains instrument-patches
using the samples.
-->
<patches>
<patch id="hard">
<play note="C" sample="git1" freq="1000" vel="88"/>
<play note="C#" sample="git1" freq="1010" vel="88"/>
<play note="D" sample="git1" freq="1020" vel="88"/>
<!-- etc. -->
</patch>
<patch id="soft">
<play note="C" sample="git2" freq="1000" vel="110"/>
<play note="C#" sample="git2" freq="1010" vel="110"/>
<play note="D" sample="git2" freq="1020" vel="110"/>
<!-- etc. -->
</patch>
</patches>
</sampler>
Parsing XML documents
To parse the XML document from its file, use:
d = DOMDocument.new("/home/jgulden/sc/sampler.xml");
or
d = DOMDocument.new;
f = File("/home/jgulden/sc/sampler.xml", "r");
d.read(f);
or
d = DOMDocument.new;
f = File("/home/jgulden/sc/sampler.xml", "r");
xmlContent = String.readNew(f);
d.parseXML(xmlContent); // parses from string
Processing XML documents
After parsing, the XML content is accessible through instances of concrete subclasses of DOMNode via the operations they provide. Examples:
d.getDocumentElement.getElementsByTagName("sample").do({ arg tag, index;
( "Sample #" ++ index ++ ", id: " ++ tag.getAttribute("id") ++ ", file: " ++ tag.getText ).postln;
// DOMElement.getText is an extension to the DOM, if the first child node
// of an element is a DOMText-node, getText retrieves the string content of it
});
or
e = d.getDocumentElement.getElement("patches");
p = e.getFirstChild;
while ( { p != nil } , {
("Patch : " ++ p.getAttribute("id")).postln;
//..doSomethingWithThePatchNode
p = p.getNextSibling;
});
As a SuperCollider-specific extension to the DOM, nodes can also be treated like Collections when traversing through their subtree:
e = d.getDocumentElement.getElement("samples");
e.do({ arg node;
("Node: " ++ node.getNodeName ++ " : " ++ node.getNodeValue).postln;
});
"-------------".postln;
// get a list of all text-nodes:
l = e.select({ arg node;
node.getNodeType == DOMNode.node_TEXT;
});
"All text-nodes: ".post; l.postln;
// get a list of all text-contents (some will be nil):
l = e.collect({ arg node;
node.getNodeValue;
});
"All text-contents:".post; l.postln;
By default, all comments and whitespace-only text-blocks will be ignored when parsing. This will usually make it easier to access the parsed data-structure, as comments are usually to be filtered out anyway. However, it may be desirable to also access the textual content of comments or whitespace, so the parser's behavious can be configured:
// Default behaviour:
d = DOMDocument.new;
f = File("/home/jgulden/sc/sampler.xml", "r");
d.read(f);
d.getDocumentElement.getFirstChild.getNodeName ++ " : " ++ d.getDocumentElement.getFirstChild.getNodeValue
The output using the default configuration is:
samples : nil
(Note: a node-value of 'nil' for element-nodes is correct, as element-nodes (XML-tags) don't carry any textual data by themselves.)
Now with the configuration to include comment-nodes in the document:
// Parse comments, too:
d = DOMDocument.new;
d.parseComments = true; // this enables comment-nodes to be parsed
f = File("/home/jgulden/sc/sampler.xml", "r");
d.read(f);
d.getDocumentElement.getFirstChild.getNodeName ++ " : " ++ d.getDocumentElement.getFirstChild.getNodeValue
This outputs:
#comment : This section contains sample references.
Creating XML documents programmatically
Instead of parsing a document from a file, you can also create new XML documents via object-oriented program operations:
var root, samplesTag, sampleTag, sampleFiles;
d = DOMDocument.new; // create empty XML document
root = d.createElement("sampler");
d.appendChild(root);
samplesTag = d.createElement("samples");
root.appendChild(samplesTag);
sampleFiles = List.new;
sampleFiles.add("/data/samples/git1.wav"); // 2 dummy entries
sampleFiles.add("/data/samples/git2.wav");
sampleFiles.do({ arg samplefile, index;
sampleTag = d.createElement("sample");
sampleTag.setAttribute( "id" , ( "git" ++ index ) );
t = d.createTextNode(samplefile); // another type of document node: a block of text
sampleTag.appendChild(t); // place text below/inside <sample>-node
samplesTag.appendChild(sampleTag); // place <sample>-tag below/inside <samples>
});
f = File("/home/jgulden/sc/samplerOut.xml", "w");
d.write(f); // output to file with default formatting
f.close;
The resulting output file is:
<sampler>
<samples>
<sample id="git0">/data/samples/git1.wav</sample>
<sample id="git1">/data/samples/git2.wav</sample>
</samples>
</sampler>
Outputting XML documents
Formatting parameters can be applied, e.g. outputting with / without beautifying indentation (which means that each child-tag is shifted an amount of doc.indent characters to the right before outputting. This way, the tree structure of the document is representeed in the formatting. However, this requires the introduction of additional blank text area, which may be unwanted in some cases):
// ... parse or create doc ...
d.preserveWhitespace = true; // neither add any whitespace on formatting nor trim when parsing (this will already practically disable indentation)
d.indent = 0; // no indentation
f = File("/home/jgulden/sc/samplerOut.xml", "w");
d.write(f);
f.close;
// or: xml = d.format; to get as string instead of writing to disk
A part of an XML document can be extracted as a subtree and be made a new document:
d = DOMDocument.new("/home/jgulden/sc/sampler.xml");
s = DOMDocument.new; // new XML document to store only a subtree in
e = d.getDocumentElement.getElement("patches");
// 'getElement(name)' is an extension to the DOM, it is equivalent to getElementsByTagName(name).firstElement, but faster implemented and easier to use
n = e.cloneNode(true); // deep==true: all children are also copied
n = s.importNode(n); // import node-tree into new document, which allows appending now
s.appendChild(n); // append as document's root node
f = File("/home/jgulden/sc/samplerOut.xml", "w");
s.indent = 1;
s.write(f);
f.close;
The resulting output file is:
<patches> <patch id="hard"> <play vel="88" sample="git1" note="C" freq="1000"/> <play vel="88" sample="git1" note="C#" freq="1010"/> <play vel="88" sample="git1" note="D" freq="1020"/> </patch> <patch id="soft"> <play vel="110" sample="git2" note="C" freq="1000"/> <play vel="110" sample="git2" note="C#" freq="1010"/> <play vel="110" sample="git2" note="D" freq="1020"/> </patch> </patches>
Some standard character-entities in text-nodes get resolved when accessing text-node's content via the non-standard methods 'getText'/'setText' instead of 'getData'/'setData'. Example:
d = DOMDocument.new.parseXML("<test>7 &lt;= 10. Letter 'A' is &#65; as an ASCII-entity.</test>");
d.getDocumentElement.getFirstChild.getText.postln;
d.getDocumentElement.appendChild(d.createTextNode(""));
d.getDocumentElement.getLastChild.setText(" Here is some more: 88 > 77.");
d.getDocumentElement.getLastChild.getText.postln;
d.getDocumentElement.getLastChild.getData.postln;
"---".postln;
d.getDocumentElement.normalize.getText.postln;
UML class-diagram of the Document Object Model (DOM) implementation
The DOM-classes have been entirely developed using a model-based approach, utilizing a UML class-diagram as the underlying conceptual model.
View the attachment DOMclasses.png.gz to see the entire UML class-diagram of this DOM implementation.
Limitations
- The DOM-Level-1 standard is out of date. It does not support any XML-namespaces and is thus restriced to basic XML usage.
- Document-type definition (DTDs) are not supported (and also regarded as being out-of-date). Luckily both namespaces and DTDs are not expected to be important in the area of applications SuperCollider is typically used for. In cases where DTD-validation is still needed, an external validator would be easy to call.
- Only simple HTML character-entities, e.g. < , & and XML ascii-entities, e.g. { , are supported.
See also: Document Object Model (DOM), Developing with the Unified Modeling Language (UML).
Attachments: DOMclasses.png.gz
jg
Related
Creating compatible XML files from Java

{kind=link}